
In short: Rolling deployments with proper AWS ELB / auto-scaling group de-registration, chef-client run, and re-registration. Script available here.
We just finished a script for our deployment pipeline, that reduces the manual effort of a deployment to a single click.
Why do we put effort to do this? Because we want to release our software as often as possible. Reducing the overhead involved in each deployment helps us to make deployments more fun :)
Background Check - The Stack
Our servers run in Amazon with a certain redundancy. Load-balancers distribute the requests to our API and the website to multiple servers in the background. These Load-balancers also report a health status of each server to an auto-scaling group, that ensures that at least X healthy servers are ready to process user requests. As most of our releases, we can do a rolling release: One server is updated at a time. During this update the other servers take over, so you as a user do not realize, that we are upgrading our software - neat, huh? Until now, we did these steps manually:
- take server out of load-balancer
- update the server
- check if the update succeeded
- put server back into load-balancer and wait for it to receive traffic
- continue from 1 until all servers are upgraded
So far, we made use of chef for machine provisioning and
orchestration. We used commands like knife ssh -C1 chef_environment:staging "sudo chef-client"
to trigger a release to our staging environment, one at a time. While this is
totally fine with the staging environment, this would be fatal in production.
Servers need to be removed from the load-balancers before taken offline, otherwise we would risk user requests being dropped and monitoring tools firing emails about broken servers.
To improve this, we wrote this little script, which sits on each EC2 instance and sets itself to StandBy (re-registering itself from the load-balancer), before performing an update.
While writing, we had these key points in mind: - self-sufficient / not dependent on another or centralized entity - as little code dependencies as possible - fails deployment when something is fishy - no configuration required - pull needed information from the environment
The Script
We picked Python to hack away & test the script within a few hours. The only dependency is Boto3 to talk with the Amazon AWS API. All information the tool needs, is pulled from the instance meta data or the Amazon AWS API, such as name of the auto scaling group, load-balancers involved, or the current health status of the instance as seen from the outside (aka the user and the load-balancers).
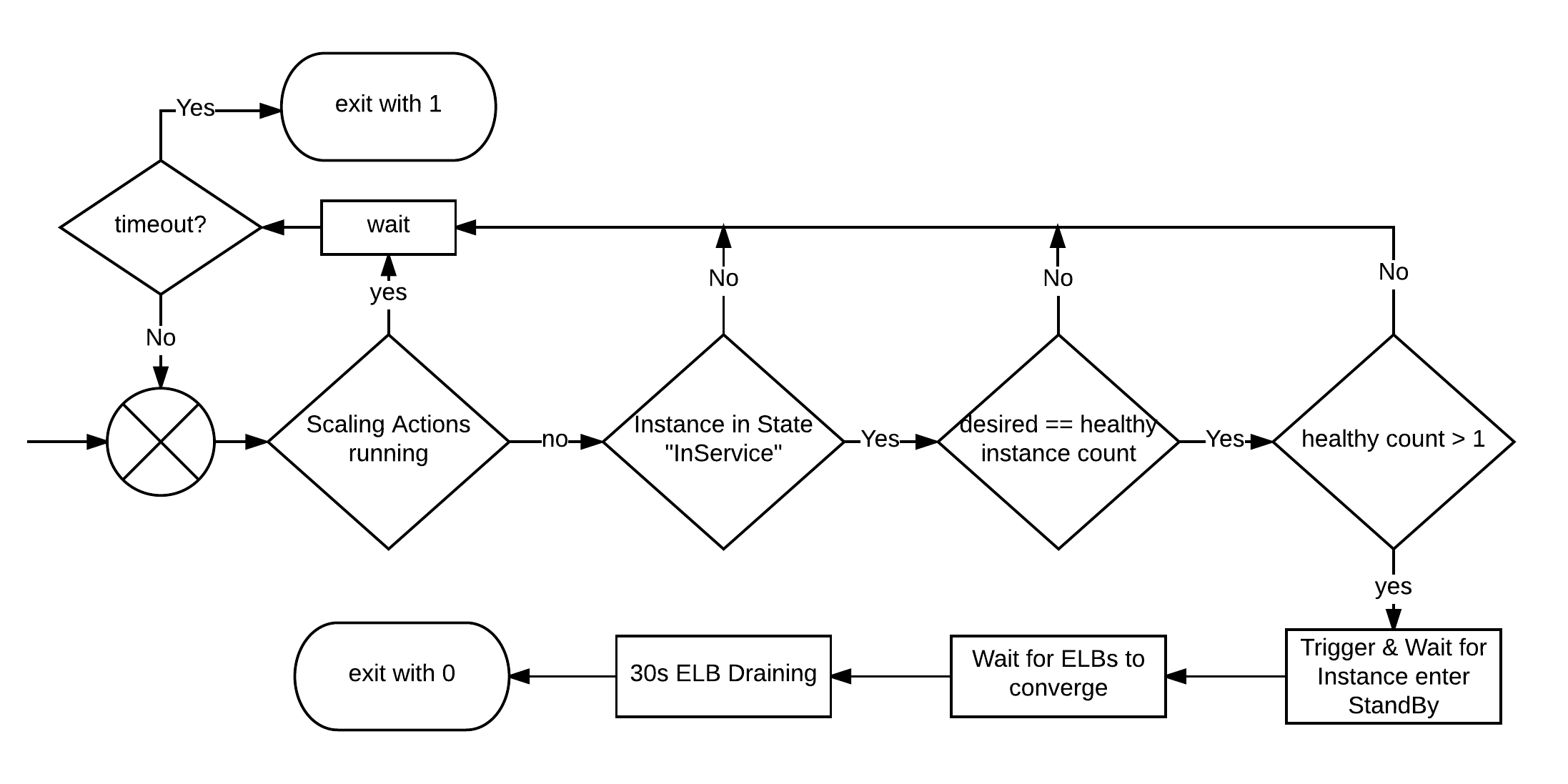 Before we deregister any instance from the auto-scaling group, we must be sure, that there are enough other instances to take over the traffic. The script assumes,
that no other instance of the script is executed concurrently, so we only have
to check if the auto-scaling group itself is performing scaling actions. If
everything is ok, the instance will set itself to
Before we deregister any instance from the auto-scaling group, we must be sure, that there are enough other instances to take over the traffic. The script assumes,
that no other instance of the script is executed concurrently, so we only have
to check if the auto-scaling group itself is performing scaling actions. If
everything is ok, the instance will set itself to StandBy state and waits for
all systems to converge. Then the script exits with code 0 (which means “everything looks good” in linux-speak). If anything is suspicious or takes too long,
the script will return another code, signaling to abort the deployment process.
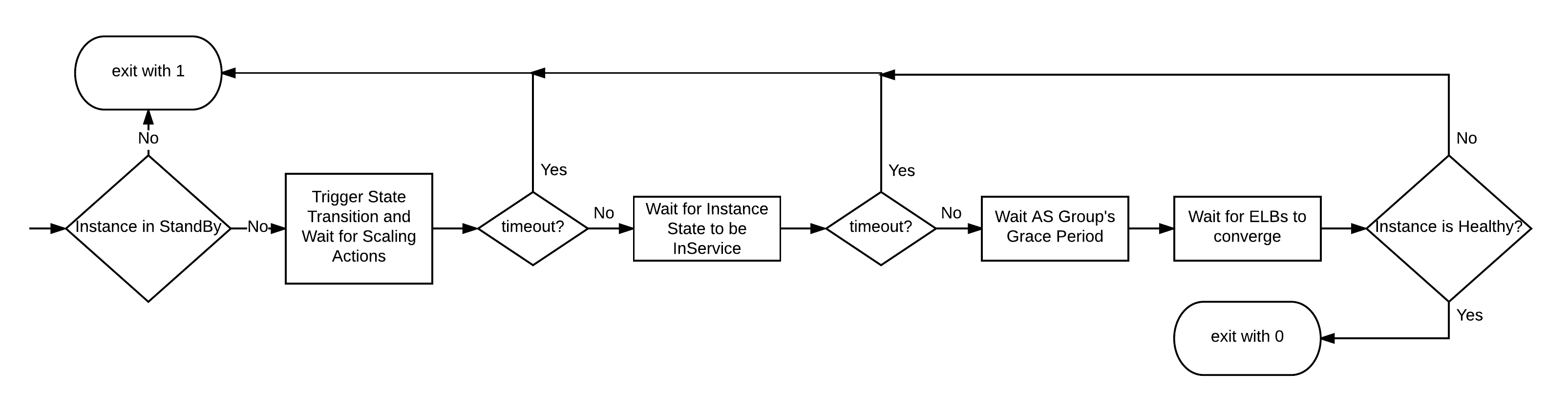
The process to entering the desired InService state, is similar: If everything
looks good: return 0, otherwiese something else.
 .
.
Putting everything together
The script is installed together with boto3 on all our servers per default.
After the first start, we can upgrade all our machines with a single command:
knife ssh -C1 --exit-on-error chef_environment:production "python balanced.py out && sudo chef-client && python balanced.py in". Since we are also human, we tend
to forget these lenghty commands and put them into a Jenkins job, so we simply have
to push a button :)
You can find the complete script on our Bitbucket account. Please feel free to shoot any question or tell us how you are tackling your deployments.
– Your Tech-Heads from Aquaplot